




It is easy to get confused by all the new AI terms. Everyone is talking about ChatGPT, but how is it different from the chatbots we have used for years? The simple answer is that Large Language Models (LLMs) are just the smarter, younger generation of Natural Language Processing (NLP). In short, they are part of the same system, just at different stages of development.
However, understanding the LLM vs NLP distinction clearly is crucial for your budget, as if you pick the wrong one, your bot is either too stupid to help or too expensive to run. This guide will help you understand the differences so you can choose wisely.
- NLP and LLMs are not rivals — they are the same technology, evolved. LLMs represent the smarter, newer generation of NLP, both serving the same goal of making computers understand human language.
- NLP matches keywords to rules; LLMs predict the next word from context. Rather than looking up pre-written answers, LLMs generate responses word by word by calculating probability based on billions of trained examples.
- Choosing the wrong AI tool does not just hurt performance — it hurts your budget. Deploying an LLM for simple tasks wastes money, while using basic NLP for complex conversations leaves users frustrated and underserved.
- NLP thrives on consistency; LLMs thrive on creativity and open-ended reasoning. Spam filters and order-tracking bots need speed and rules, while content generation and advanced virtual agents demand dynamic, context-aware responses.
- LLMs feel human because they learned language from billions of real pages of text. Models like GPT-4, Claude, and Llama studied vast internet and book data, enabling them to maintain natural conversation flow without a script.
What is natural language processing (NLP)?

Natural Language Processing (NLP) is the technology that allows computers to understand human language. While computers natively speak in binary code, humans speak in words and sentences. NLP acts as the translator between these two worlds.
NLP analyzes the structure of your sentence rather than understanding its deeper meaning. The system scans your text for specific keywords and grammatical patterns to determine your goal. This process is known as intent classification.
For example, when you type "track my order," the software spots those keywords and matches them to a shipping database. It does not "know" you are waiting for a package. It simply follows the programmed rule to retrieve a tracking number.
Because it relies on clear instructions, this technology is excellent for tasks that require speed and consistency rather than creativity. You likely encounter standard NLP in everyday tools such as:
- Spam filters that automatically move suspicious emails to your junk folder.
- Basic translation apps that convert text word-for-word between languages.
- NLP chatbots that guide you through menu options to check an order status.
What is a large language model (LLM)?

In contrast to NLP, which follows strict rules, a Large Language Model (LLM) is a type of artificial intelligence trained on vast amounts of text. These models read billions of pages from the internet and books to learn how humans communicate.
LLMs work by calculating probability to predict the next word in a sentence. When you ask a question, the model does not look up a pre-written answer in a database. Instead, it analyzes the context of your request and generates a new response word by word. This allows models like GPT-4, Claude, and Llama to handle complex instructions and maintain a natural conversation flow that feels surprisingly human.
Because they generate fresh content dynamically, these tools are powerful for tasks that require creativity or reasoning. They have quickly become essential for various modern applications, such as:
- Content generation for writing emails, code, or marketing copy from scratch.
- Summarization tools that turn long documents into short, easy-to-read briefs.
- Advanced virtual agents that can answer open-ended questions without a script.
NLP vs. LLM: 5 Key differences
Actually, traditional NLP is like Microsoft Excel: it is rigid, precise, and perfect for sorting data into rows and columns. An LLM is like a smart consultant: it can read the data, understand the context, and write a comprehensive summary report for you.
Let's look at the comparison table below:
| Feature | NLP | LLM |
|---|---|---|
| 1. Flexibility | Rigid. Fails if the user doesn't use exact keywords. | Context-aware. Understands slang, typos, and nuance. |
| 2. Training data | "Supervised." Needs labeled data for every single task. | "Unsupervised." Learns general patterns from the internet. |
| 3. Output | Classification. Sorts data or assigns labels (e.g., "Spam"). | Generation. Creates new content (e.g., writes an email). |
| 4. Cost & Speed | Lightweight. Cheap, fast, runs on standard CPUs. | Heavy. Expensive, slower, requires powerful GPUs. |
| 5. Scope | Single-task. Good at one specific job (Specialist). | Multi-task. Can handle almost any language task (Generalist). |
Flexibility: Rule-following vs. Context-understanding
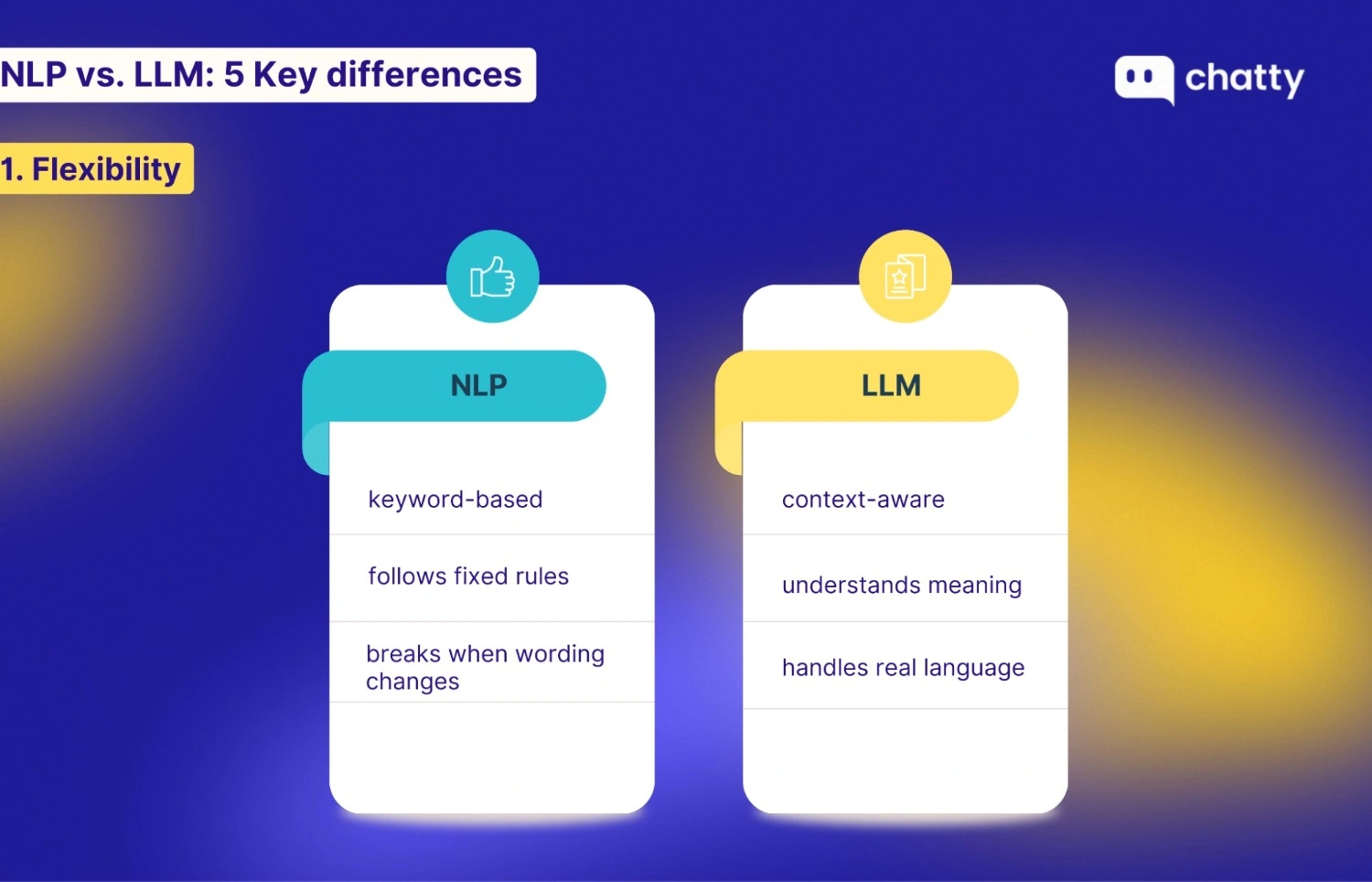
Traditional NLP lacks flexibility because it relies on strict rules and specific keywords. For example, if you program a chatbot to recognize the word "refund", it works perfectly when a customer uses that exact word. However, if a customer types "I want my money back" without saying "refund", the system often fails because it cannot find the keyword it was told to look for.
In contrast, LLMs offer high flexibility because they focus on natural language understanding (NLU) to grasp the meaning behind the words. They do not rely on a list of specific keywords. This allows the system to easily handle:
- Slang terms
- Misspelled words
- Complex sentence structures
Training data: Specialized labeling vs. Massive pre-training

Traditional NLP uses supervised learning, which requires humans to manually prepare the data. To teach a model to recognize invoices, engineers must collect thousands of documents and explicitly label each one as "Invoice" or "Not Invoice". The model learns only from these specific, labeled examples.
On the other hand, LLMs use unsupervised learning, meaning their training data consists of massive amounts of raw text. Instead of relying on manual labels, these models read billions of pages from books, websites, and articles. By analyzing this vast amount of information, they learn general patterns in language and grammar, and gather facts on their own without needing a human to tag every single piece of data.
Output: Classification vs. Generative creation

Traditional NLP functions as an analytical tool, so its output is usually a label or a score. If you feed it a customer email, it analyzes the text and provides data points such as:
- Topic tags
- Sentiment scores
- Spam detection labels
On the contrary, LLMs are generative tools, so their output is new, original content. If you feed that same customer email to an LLM, it does not just categorize it. It can draft a full, polite response to the customer.
In general, traditional NLP is best for sorting information, while LLMs are designed for creating new communication.
Cost & Speed: Efficiency vs. Power

When comparing cost and speed, traditional NLP is the clear winner for simple tasks. Because it follows simple rules, it is very lightweight. You can run a standard NLP model on a basic laptop and process requests in milliseconds. This makes it extremely cost-effective to operate, which is ideal for processing large volumes of data quickly.
LLMs require significant computing power, which drives up costs. Because they calculate complex probabilities for every single word they generate, they need expensive, high-performance servers (GPUs) to run. This makes them slower and much more expensive per request. For simple tasks that do not require complex reasoning, using an LLM is often unnecessary and expensive.
Scope: Single-purpose vs. Multi-purpose
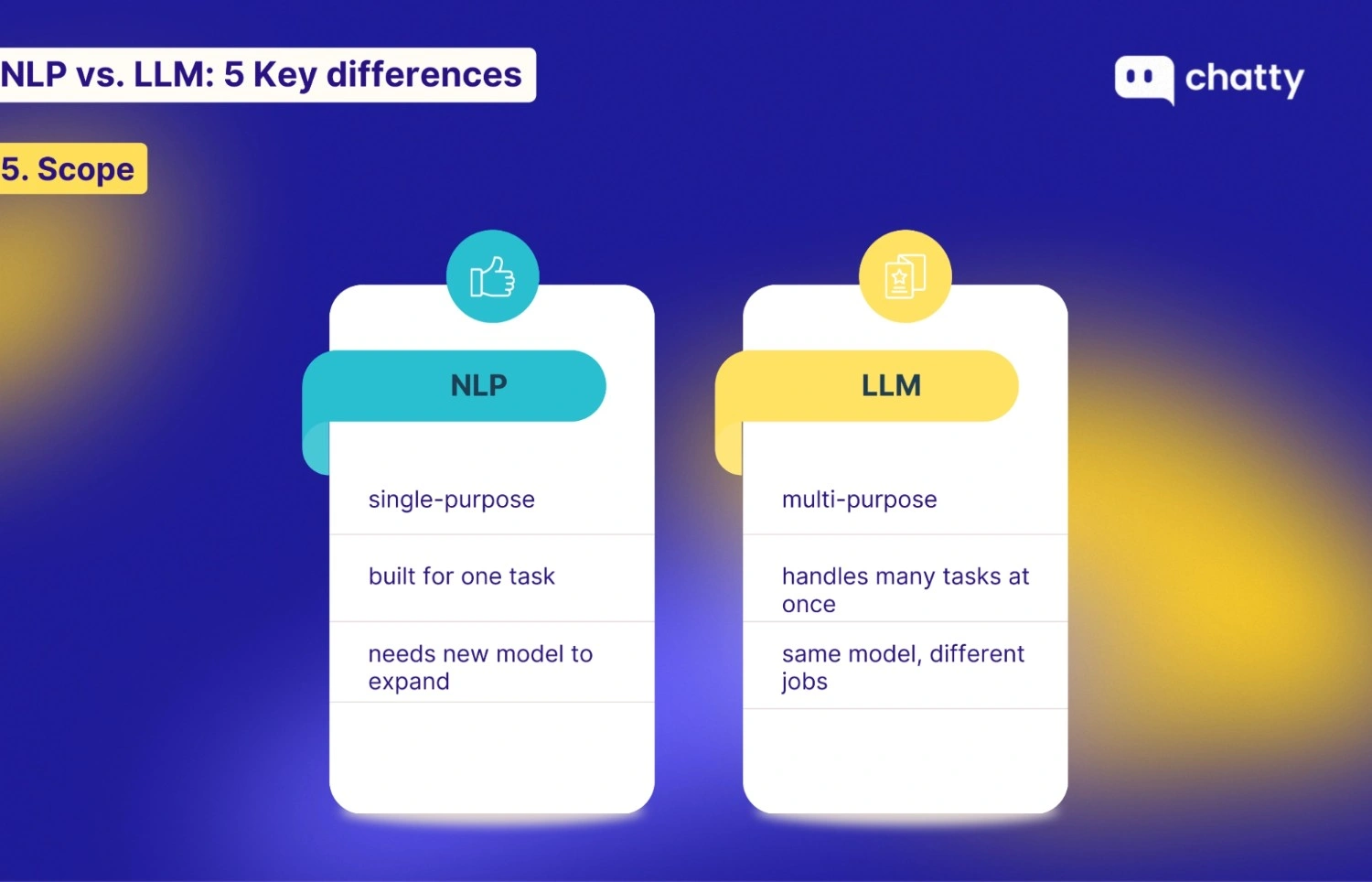
Traditional NLP has a narrow scope because it is designed for a single purpose. If you build a model to filter spam emails, that is all it can do. It cannot translate languages or summarize news. If you want it to perform a new task, you must build a completely new model from scratch.
However, LLMs have a broad scope and act as multi-purpose tools. A single model like GPT-4 can handle widely different tasks in the same conversation, including:
- Writing computer code
- Translating languages
- Summarizing meetings
This versatility makes LLMs very powerful, but it also makes them harder to control compared to the focused nature of traditional NLP.
When to choose NLP, LLM, or hybrid?
When to prioritize NLP
Traditional NLP is the best choice when precision and speed are your main goals. It works perfectly for structured tasks with only one correct answer. You should stick with NLP if you need:
- Strict compliance: Situations where the bot must follow an exact legal script without changing a single word.
- Simple actions: Tasks like resetting a password, checking an order status, or booking a meeting room.
- Low cost at scale: Processing millions of simple queries without racking up a massive server bill.
When to prioritize LLM
LLM shines when flexibility is required. They are the right tool when you need to handle messy, unpredictable human conversations. You should switch to an LLM if you need:
- Complex reasoning: Answering open-ended questions that require summarizing multiple documents.
- Creative writing: Drafting emails, personalizing marketing messages, or rewriting technical jargon into plain English.
- Handling ambiguity: Understanding vague complaints where the customer does not use specific keywords.
When to use hybrid (recommended for most customer chatbots)
Use a hybrid chatbot when you have to balance fluency and accuracy, for example:
- Customers ask the same policy questions in 20 different ways, especially in peak season.
- You must answer from approved sources like shipping, returns, warranty, and payment terms.
- You want a bot that can handle messy messages, but you still need predictable handoffs to humans.
- You need a feedback loop that shows what the bot could not answer, so you can tighten coverage over time.
In a hybrid bot, NLP and LLM have different jobs:
- NLP routes the conversation and captures structure. This includes detecting intent, pulling key entities such as order numbers, and sending simple requests to preset flows.
- LLM writes the final message in clean, human language using the facts already pulled from your store and knowledge base.
Chatty perfectly illustrates how this hybrid model works in practice. It strictly separates "finding the facts" (NLP/Retrieval) from "writing the answer" (LLM). This separation helps prevent the AI from hallucinating while keeping the conversation smooth.
Here are details about how Chatty balances these two technologies:
- Training data: This impactful feature uses strict retrieval logic to lock onto your store's real data. It ensures the AI never hallucinates by instantly pulling the exact policy or product spec needed before writing a single word.
- AI training: This is where the LLM stands out. The AI Training module amazingly transforms dry facts into on-brand conversations, ensuring your bot sounds exactly like your best human agent rather than a cold machine.
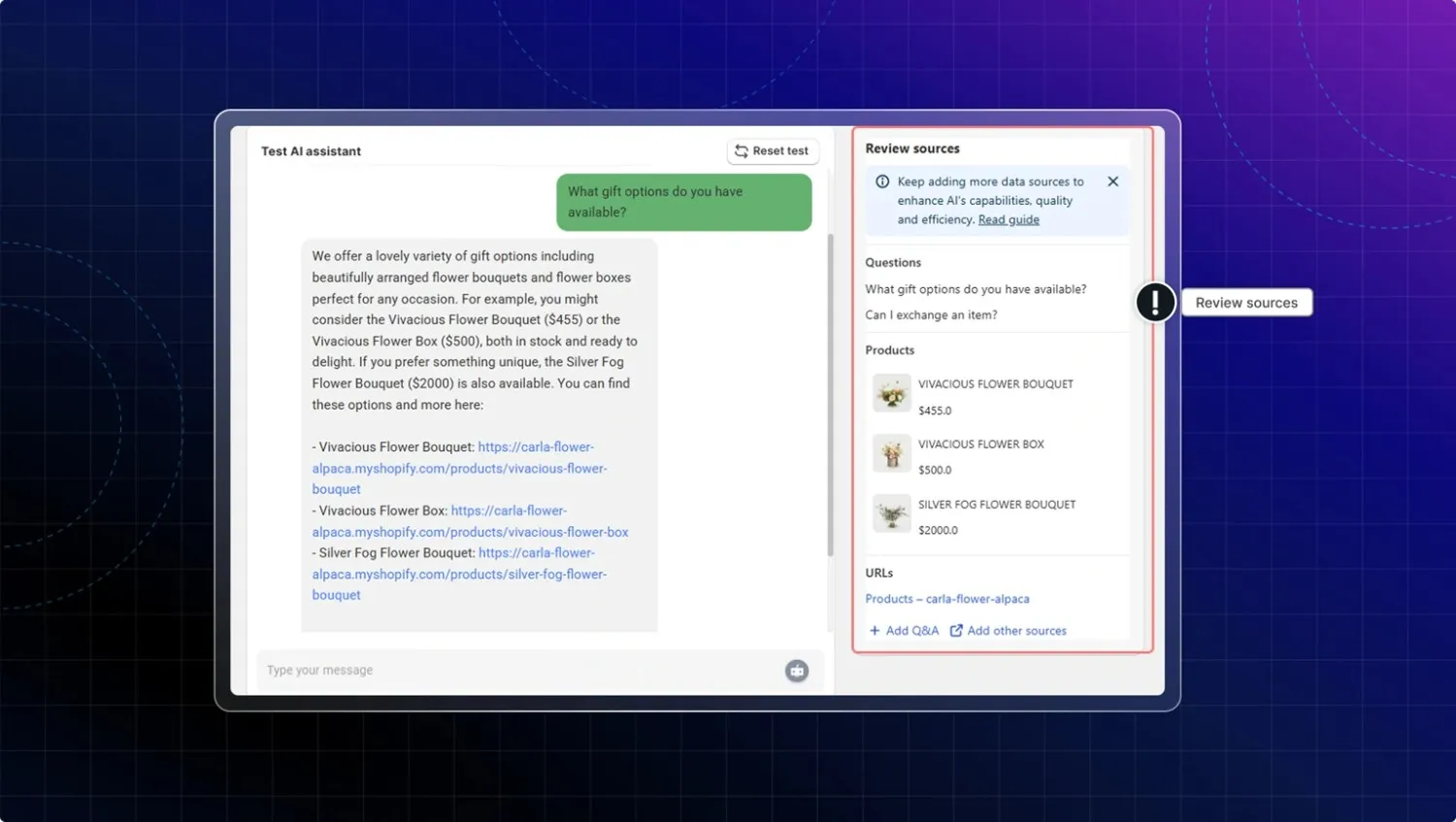
- Test & optimize AI: A highly recommended tool for accuracy. The Unresolved Questions and Review sources give you total visibility, allowing you to check exactly which source the AI used to build its answer and fix any gaps immediately.
- Scenarios: This powerful mechanism guides the AI through complex situations. Using Scenarios lets you combine specific triggers with flexible responses. This ensures that tricky interactions, like returns, are handled smoothly every time.
Future trends: Where NLP and LLMs merge
In the coming years, we will see a shift away from standalone AI experiments. The future lies in orchestrated systems where NLP and LLMs are deployed side-by-side, allowing businesses to balance the cost of automation with the quality of customer experience. Below are the trends driving this convergence.
Hybrid becomes default
More teams are moving to a split system in which each part performs one specific job well. In practice, NLP handles the "must be correct" layer, such as intent detection and order number collection. The LLM then handles the "must sound natural" layer, turning that data into a polite, clear reply.
Practical setup most teams use:
- NLP for detection: It identifies the user's goal, like a refund request, and ensures required details, like email addresses, are collected first.
- LLM for writing: It takes those details and writes a friendly response with the correct tone and timeline.
Klarna proves the power of this approach as they did not run everything through one free chat model. Their assistant routes each request into a specific scenario or task first, then generates the reply using prompts tuned for that scenario. That routing step is the "hybrid" part in practice: decide the right path and collect the required details before writing. And it worked at scale, with Klarna reporting a 25% drop in repeat inquiries after launch.
Grounded answers are mandatory
As AI expands, sounding right is no longer enough. Companies now demand answers that point back to approved documents. If the system cannot find evidence in your internal help center, the new standard is to ask a clarifying question or hand off to a human rather than guessing.
What this means for your workflow:
- Search first: Always check your internal docs for the answer before replying.
- Don't guess: If no relevant content is found, route the chat to an agent immediately.
Right-size models plus orchestration
The smart trend is to stop using one giant model for everything. Systems now automatically route simple work to lighter, faster models and save the powerful LLMs for complex reasoning.
A practical rule set for support:
- Lightweight models: Use them for simple tasks like intent detection or spam filtering.
- Heavyweight LLMs: Call these only when the customer is emotional, confused, or needs a detailed explanation.
DoorDash uses this exact strategy to keep voice support fast: they chose Claude 3 Haiku on Amazon Bedrock for speed, rather than pushing every call through a slower, heavier model. Their contact center flow pulls the right help content first, then lets the model turn those facts into the final reply. The standout outcome is response latency of 2.5 seconds or less, which matters a lot for real-time voice support.
Quality first measurement
Teams are moving beyond simple deflection rates to judge success based on correctness and handoff quality. While automation volume matters, true productivity gains come from quality control.
Metrics that matter now:
- Grounded answer rate: The percentage of bot replies that cite a clear source from your knowledge base.
- Hallucination rate: How often the AI invents wrong answers, tracked specifically by topic, like refunds or shipping.
- Handoff quality: The percentage of escalations that include a full summary and customer details so agents do not have to start over.
Conclusion
Ultimately, the LLM vs NLP distinction is fading as modern tools increasingly merge them into one seamless engine. We think the future belongs to bots that can follow strict instructions while still sounding like a friendly human, which is exactly what the hybrid model delivers. You can experience this evolution firsthand by installing Chatty and watching your support quality level up.
FAQ
Yes. NLP is the broad field of getting computers to work with human language, and LLMs are a newer type of model inside that field that can understand and generate text.
Probably not. Traditional NLP is still useful when you need cheap, fast, and predictable outputs like intent tags, entity extraction, or spam filtering, while LLMs are better when you need flexible language understanding and writing.
For most support bots, a hybrid is best: use lightweight NLP-style logic to route the request and collect required details, then use an LLM to write the final reply. Ground the LLM with retrieval from your help center or internal docs so answers stay tied to approved content.
Yes. OpenAI defines hallucinations as plausible but false statements generated by language models. Traditional NLP systems usually fail differently: they tend to misclassify an intent or miss an entity, rather than inventing new "facts."
Rarely. A common approach is to use a pre-trained model and add your business knowledge through retrieval (RAG), which pulls facts from your own documents right before the model answers. OpenAI also notes that fine-tuning is not a good fit for "teaching the model new knowledge," so retrieval is usually the first choice, and fine-tuning is mainly for style or format.





